Prism — Architecture¶
Audience: Architects, tech leads, senior engineers evaluating design decisions and cross-module impact.
Context and Purpose¶
Prism exists to solve a separation-of-concerns problem: AI coding agents need deep, live codebase context, but building that context into every agent session is prohibitively expensive in tokens, latency, and engineering effort. Prism externalizes codebase intelligence into a dedicated, stateful service that any MCP-compatible agent can query.
The architectural drivers are:
- Sub-second query latency. AI agents make tool calls synchronously during conversations. A search that takes 5 seconds breaks the conversational flow. The design targets P95 < 500ms for all MCP queries.
- Cost isolation for tenant data. Code indexes are large (hundreds of megabytes per tenant) and benefit from isolated storage for both performance and data separation. Per-schema PostgreSQL isolation provides this without the overhead of per-tenant database instances.
- GCP-native alignment. Swisper already runs on GCP with Vertex AI and PostgreSQL+pgvector. Prism reuses this infrastructure rather than introducing new vendors.
- Stateless gateway, stateful storage. The Cloud Run gateway handles no session state — tenant context comes from the JWT or developer token on each request. This allows horizontal scaling and zero-downtime deployments.
Prism's responsibility ends at the MCP protocol boundary. It does not generate code, orchestrate agents, or interact with users directly — it provides precise context to agents that do.
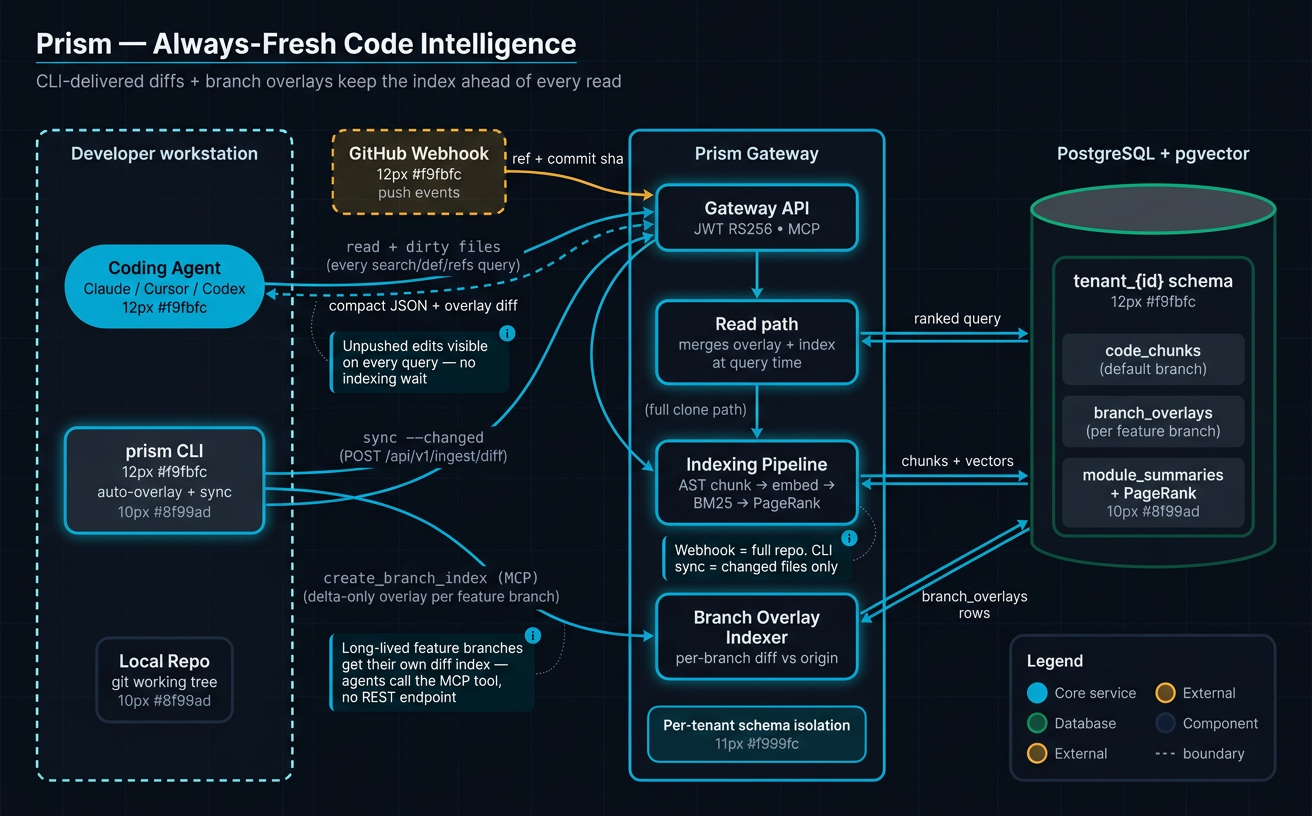
Architecture Overview¶
Prism runs as a hosted Streamable HTTP MCP server on Cloud Run. AI clients connect via the MCP protocol over HTTPS. Authentication uses either developer tokens (permanent, generated in the Console) or Firebase RS256 JWTs. Per-repo scoping is handled via the X-Prism-Repo HTTP header.
graph TB
subgraph Clients ["AI Clients"]
CURSOR["Cursor"]
CLAUDE["Claude Code"]
WIND["Windsurf"]
end
subgraph CloudRun ["Cloud Run — europe-west1"]
GATEWAY["Prism Gateway\nStarlette ASGI\nStreamable HTTP MCP"]
AUTH["Auth Layer\nJWT RS256 + Developer Tokens"]
TOOLS["MCP Tool Handlers\n18 tools: ping, whoami, list_repos,\nsearch_code, search_docs, get_module_map,\nget_file_outline, get_function_body,\nget_symbol_definition, find_references,\nget_dependencies, get_architecture,\nget_repo_context, get_codebase_conventions,\nprepare_to_edit, check_exists,\ncreate_branch_index, delete_branch_index"]
SEARCH["Search Intelligence\nIntent Classification\n4-way Hybrid + RRF"]
RERANKER["Google Semantic\nReranker"]
INGEST["Ingestion API\n/ingest/file, /ingest/diff,\n/ingest/webhook"]
CONSOLE_API["Console API\nRepo management,\nDeveloper tokens"]
QUEUE["Job Dispatcher\nDirect or Cloud Run Jobs"]
end
subgraph IndexWorker ["Indexing Worker"]
TIER3["Tier 3 Handler\nClone → Chunk → Embed\n→ Store → RepoMap"]
CHUNKER["AST Chunker\nTree-sitter\n48 languages"]
end
subgraph GCP ["GCP Data Layer — europe-west1"]
PGVECTOR["Cloud SQL PostgreSQL 16\npgvector 0.8.1\nPer-tenant schemas"]
VERTEX["Vertex AI\ngemini-embedding-001\n2000 dimensions"]
RANKER["Vertex AI\nSemantic Ranker\nsemantic-ranker-fast-004"]
end
subgraph GitHub
WEBHOOK["Push Webhook"]
REPO["Git Repository"]
end
CURSOR -->|"MCP over HTTPS\n+ X-Prism-Repo header"| GATEWAY
CLAUDE -->|"MCP over HTTPS"| GATEWAY
WIND -->|"MCP over HTTPS"| GATEWAY
GATEWAY --> AUTH
AUTH --> TOOLS
TOOLS --> SEARCH
SEARCH --> PGVECTOR
SEARCH --> VERTEX
SEARCH --> RERANKER
RERANKER --> RANKER
GATEWAY --> INGEST
GATEWAY --> CONSOLE_API
INGEST -->|"webhook"| QUEUE
QUEUE --> TIER3
TIER3 --> CHUNKER
TIER3 --> VERTEX
TIER3 --> PGVECTOR
TIER3 -->|"shallow clone"| REPO
WEBHOOK --> INGEST
CONSOLE_API --> PGVECTORThe search pipeline is the core of the system: queries flow through a 4-way hybrid retrieval (vector similarity + BM25 keyword + description vector + exact text match), fused via Reciprocal Rank Fusion (RRF), then optionally re-ranked by the Google Semantic Reranker. A search intelligence layer classifies query intent and boosts results accordingly.
Component Responsibilities¶
| Component | Location | Responsibility |
|---|---|---|
| Prism Gateway | prism/gateway/app.py |
Starlette ASGI application providing the Streamable HTTP MCP endpoint at /mcp. Manages auth, rate limiting, tenant context via ContextVars, and routes to MCP tool handlers. |
| Auth Layer | prism/gateway/auth.py |
Dual-mode authentication: validates prism_* developer tokens via DB lookup (never expire) and Firebase RS256 JWTs via JWKS (1h expiry). Extracts tid claim for tenant routing. |
| MCP Tool Handlers | prism/gateway/mcp_tools.py, mcp_tools_caps.py, tool_definitions.py |
Implements 18 MCP tools across discovery (ping, whoami, list_repos), search (search_code, search_docs), navigation (get_module_map, get_file_outline, get_function_body, get_symbol_definition, find_references, get_dependencies), architecture (get_architecture, get_repo_context, get_codebase_conventions), edit discipline (prepare_to_edit, check_exists), and branch lifecycle (create_branch_index, delete_branch_index). Handles path normalization, compact/full output modes, per-repo scoping, branch-overlay-aware reads, diagnostic hints on empty results, and pg_trgm fuzzy symbol matching. |
| Search Intelligence | prism/gateway/search_intelligence.py |
Classifies query intent (definition lookup, usage search, architectural question), applies intent-based result boosting, enriches responses with confidence scores and next-action suggestions. |
| Hybrid Search Engine | prism/search/hybrid_search.py |
4-way retrieval: vector cosine similarity, BM25 full-text, description vector, and exact ILIKE match. Results fused via RRF scoring. |
| Google Semantic Reranker | prism/search/reranker.py |
Optional post-retrieval re-ranking via Vertex AI Ranking API (semantic-ranker-fast-004). Configurable via PRISM_RERANKER_ENABLED and PRISM_RERANKER_TYPE. |
| VertexAI Embedder | prism/embeddings/vertex_provider.py |
Generates 2000-dimensional embeddings via gemini-embedding-001 on Vertex AI. Uses RETRIEVAL_DOCUMENT task type for indexing, RETRIEVAL_QUERY for search. Concurrency limited to 5 parallel requests. |
| pgvector Storage Engine | prism/storage/pgvector_engine.py |
asyncpg connection pool against Cloud SQL. Sets search_path per tenant. Provides HNSW vector cosine search and tsvector BM25 queries. |
| Schema Manager | prism/storage/schema.py |
Creates and drops per-tenant schemas. Normalizes tenant IDs (strips tenant- prefix, replaces hyphens). Applies DDL from schema_init.sql. |
| Developer Tokens | prism/storage/developer_tokens.py |
Validates prism_* tokens via DB lookup. Tokens are permanent, org-scoped, and created via the Console API. |
| Ingestion API | prism/ingestion/router.py, handlers.py |
Three endpoints: /ingest/file (single file), /ingest/diff (commit changes), /ingest/webhook (GitHub push with HMAC validation). |
| AST Chunker | prism/chunking/ast_chunker.py |
Tree-sitter-based code chunking. Extracts symbol names, kinds, signatures, and docstrings. Supports 48 languages. |
| Job Dispatcher | prism/queue/dispatcher.py |
Routes indexing jobs to either direct asyncio execution (dev/test) or Cloud Run Jobs (production). Controlled by PRISM_QUEUE_MODE. |
| Tier 3 Handler | prism/tier3/handler.py |
Full reindex logic: shallow git clone, AST chunking, embedding generation, chunk storage, and PageRank module map rebuild. |
| RepoMap Builder | prism/repomap/builder.py |
Builds a PageRank-ranked dependency graph from Tree-sitter ASTs. Partitioned per top-level directory for monorepo support. |
| Console API | prism/gateway/console_routes.py |
REST endpoints for the Prism Console: repo registration, indexing status, trigger reindex, developer token CRUD, description backfill. |
| Wiki Generation Pipeline | console_api/services/wiki_agent.py |
Orchestrates wiki generation for the Console API: orient, TOC planning, page writing, and incremental page persistence. Retries transient Anthropic failures, reuses stored TOC checkpoints on regenerate, records failed_pages metadata in exploration_plan, and emits complete_with_errors when partial output is preserved. |
| Config | prism/config.py |
Immutable PrismConfig dataclass populated from environment variables. Controls embedding provider, database, auth, rate limits, queue mode, and reranker settings. |
Data Model¶
Prism uses three schema namespaces in Cloud SQL PostgreSQL 16.
Global schema (prism)¶
Shared across all tenants. Contains tenant registry, repo registry, usage tracking, and job management.
| Table | Purpose | Key Columns |
|---|---|---|
tenants |
Tenant registry | tenant_id UUID, name VARCHAR, plan VARCHAR(20), rate_limit_daily INT |
repos |
Repository registry | repo_id UUID, tenant_id UUID, full_name VARCHAR(255), webhook_secret VARCHAR(64), repo_root_prefix TEXT |
usage_log |
Per-request usage tracking | tenant_id UUID, tool_name VARCHAR(64), query_tokens INT, latency_ms INT |
index_jobs |
Indexing job state machine | job_id UUID, repo_id UUID, status VARCHAR(20), started_at TIMESTAMPTZ, error_message TEXT |
developer_tokens |
Permanent API tokens | token_hash VARCHAR(64), tenant_id UUID, label VARCHAR(100), created_at TIMESTAMPTZ |
Per-tenant schema (tenant_{name})¶
One schema per tenant. Created on tenant onboarding.
| Table | Purpose | Key Columns |
|---|---|---|
code_chunks |
Primary search table — one row per semantic code chunk | repo_id UUID, embedding vector(2000), content_tsv tsvector, file_path TEXT, start_line INT, end_line INT, language VARCHAR(32), symbol_name VARCHAR(512), symbol_kind VARCHAR(64), signature TEXT, docstring TEXT, description TEXT |
module_summaries |
PageRank repo map per directory | repo_id UUID, module_path TEXT, summary TEXT, symbols JSONB, page_rank FLOAT |
repo_metadata |
File-level change tracking | repo_id UUID, file_path TEXT, change_type VARCHAR(20), commit_sha VARCHAR(40), timestamp TIMESTAMPTZ, indexed_at TIMESTAMPTZ |
Indexes¶
code_chunks_embedding_idx: HNSW onembedding vector_cosine_ops,m=16, ef_construction=64code_chunks_tsv_idx: GIN oncontent_tsvfor BM25 full-text searchcode_chunks_repo_file_idx: B-tree on(repo_id, file_path)for file-level deduplicationcode_chunks_symbol_name_idx: B-tree onsymbol_namefor definition and reference lookupscode_chunks_symbol_trgm_idx: GIN onsymbol_name gin_trgm_opsfor pg_trgm fuzzy symbol matching (requiresCREATE EXTENSION IF NOT EXISTS pg_trgm;run once as superuser)
Key Design Decisions¶
Decision: Per-schema tenant isolation (chosen) vs row-level security (rejected)¶
- Chosen: Each tenant gets a separate PostgreSQL schema (
tenant_{name}). Per-tenant HNSW indexes.search_pathset per request. - Rejected: Row-level security with a
tenant_idcolumn on all tables, sharing a single HNSW index. - Rationale: Code indexes are large and write-heavy. A tenant with 10 million vectors does not degrade search performance for other tenants with per-schema isolation. Separate HNSW indexes allow per-tenant tuning. The operational cost (schema migrations x N tenants) is acceptable because Prism's schema is intentionally simple and stable.
Decision: Streamable HTTP MCP transport (chosen) vs SSE transport (rejected)¶
- Chosen: MCP Streamable HTTP transport at
/mcp— single endpoint, stateless, JSON responses. - Rejected: SSE +
/messagestransport (was a placeholder in early versions). - Rationale: Streamable HTTP is the MCP SDK's recommended transport for stateless servers. It works naturally with Cloud Run's request-response model, avoids long-lived SSE connections that complicate load balancing, and supports the
stateless=Truemode where tenant context comes from ContextVars per request.
Decision: Developer tokens (chosen) vs JWT-only auth (rejected as sole method)¶
- Chosen: Dual auth: permanent
prism_*developer tokens (DB-validated) alongside Firebase RS256 JWTs. - Rejected: JWT-only authentication requiring hourly token refresh.
- Rationale: JWT tokens expire after 1 hour, which is unacceptable for MCP configs that live in static files (
.cursor/mcp.json). Developer tokens never expire, are generated once in the Console, and eliminate the token refresh problem entirely. JWTs are retained for the Console web app where OAuth flows are natural.
Decision: 4-way hybrid search + RRF + Semantic Reranker (chosen) vs vector-only search (rejected)¶
- Chosen: Four retrieval legs (vector similarity, BM25 keyword, description vector, exact ILIKE) fused via Reciprocal Rank Fusion, then optionally re-ranked by Google's Semantic Ranker.
- Rejected: Vector-only search (single embedding similarity query).
- Rationale: Vector search excels at semantic similarity but misses exact matches (e.g., searching for a specific function name). BM25 catches keyword matches. The exact leg catches substring matches that neither vector nor BM25 surface. RRF fusion balances all four signals without requiring tuned weights. The semantic reranker provides a final quality pass using a cross-encoder model.
Decision: gemini-embedding-001 (chosen) vs VoyageAI voyage-code-3 (rejected as primary)¶
- Chosen:
gemini-embedding-001via Vertex AI, 2000 dimensions. - Rejected: VoyageAI
voyage-code-3(1024 dims, external vendor dependency). - Rationale: Swisper production already uses
gemini-embedding-001at 2000 dimensions. Prism reuses the same model for infrastructure consistency, no external vendor, and GCP-native auth.
Interfaces and Contracts¶
MCP Tools (primary external interface)¶
MCP-compatible clients connect via Streamable HTTP at https://prism-gateway-xvsemyikqq-oa.a.run.app/mcp.
| Tool | Signature | Returns |
|---|---|---|
ping |
() |
{status, timestamp, tool_count} |
whoami |
() |
Tenant + token identity, default repo if set |
list_repos |
() |
All repos visible to the current tenant |
search_code |
(query, limit?, path_filter?, source_only?, include_file_context?, branch?) |
4-leg RRF response with results, confidence, provenance, query_intent, next_actions, indexed_at, index_age_seconds |
search_docs |
(query, limit?, path_filter?) |
Same shape as search_code, filtered to markdown / .mdc files |
get_module_map |
(path?, query?, max_entries?, include_change_velocity?) |
PageRank-sorted module entries with file_path, tier (core/significant/peripheral), relative_score, summaries |
get_file_outline |
(file_path, repo?) |
Ordered symbol list with name, kind, signature, line range; nested class hierarchy |
get_function_body |
(symbol) |
Full source of one function/class/method |
get_symbol_definition |
(symbol or symbols[]) |
Definition record on hit; {suggestions[]} via pg_trgm on miss; batch up to 20 |
find_references |
(symbol or symbols[], reference_type?) |
Grouped: definitions, imports, assignments, callers; source_only strips test noise; batch up to 10; fuzzy_matches on miss |
get_dependencies |
(path, depth?) |
Module-level import graph (depends-on / depended-on-by) |
get_architecture |
(mode, component_id?) |
System overview (mode 1) or component drill-down (mode 2) — Leiden components, LLM summaries, divergence flags, top entry points |
get_repo_context |
(sections?) |
Vision / architecture / readme / decisions docs, filterable by section |
get_codebase_conventions |
(query?) |
Inferred conventions + relevant .cursor/rules sections |
prepare_to_edit |
(symbol) |
Pre-edit bundle: source + top callers + test files + relevant rules + public-API warnings |
check_exists |
(intent) |
Up to 5 existing helpers ranked by description-vector similarity |
create_branch_index / delete_branch_index |
(branch) |
Overlay lifecycle for long-lived feature branches |
Authentication¶
Two token types are accepted in the Authorization: Bearer <token> header:
| Type | Format | Validation | Expiry |
|---|---|---|---|
| Developer token | prism_* prefix |
DB lookup in prism.developer_tokens |
Never |
| Firebase JWT | RS256 signed | JWKS at googleapis.com/...securetoken |
1 hour |
Required JWT claims: sub, tid (tenant ID for schema routing), exp, iat.
Per-repo scoping¶
The X-Prism-Repo HTTP header carries the GitHub full name (e.g., Acme/backend). The gateway derives a deterministic repo_id via uuid5(NAMESPACE_DNS, full_name.lower()) — names are lower-cased before hashing to prevent case-variant mismatches. The same normalization is applied in the ingestion and Tier 3 paths. For single-repo tenants, the header is optional (auto-detected).
Ingestion API¶
| Endpoint | Method | Auth | Caller |
|---|---|---|---|
/api/v1/ingest/file |
POST | Bearer token | File-level sync |
/api/v1/ingest/diff |
POST | Bearer token | Commit-level sync |
/api/v1/ingest/webhook |
POST | X-Hub-Signature-256 HMAC |
GitHub push webhook |
Console API¶
| Endpoint | Method | Purpose |
|---|---|---|
POST /api/v1/repos |
POST | Register a repo, create tenant schema |
GET /api/v1/repos/{id}/status |
GET | Indexing status |
POST /api/v1/repos/{id}/index |
POST | Trigger full/incremental reindex |
POST /api/v1/developer-tokens |
POST | Create developer token |
DELETE /api/v1/developer-tokens/{id} |
DELETE | Revoke developer token |
Wiki generation resilience contract¶
The Console API's wiki generation path is resumable at the TOC boundary. run_generation_v3() persists exploration_plan["toc"] before page writes begin and, on subsequent full generations, loads that stored TOC whenever it exists. Existing wiki_pages.section_key values determine which pages are skipped, so a regenerate writes only missing pages instead of replanning the wiki structure.
All Anthropic messages.create calls in the wiki pipeline are wrapped in _llm_call_with_retry() with exponential backoff for timeouts, connection failures, rate limits, and 5xx responses. Page orchestration still caps tool-loop expansion and falls back to a final tool-free write so a single noisy page does not abort the entire generation.
| Field / state | Location | Meaning |
|---|---|---|
exploration_plan.toc |
console.wiki_generations |
Canonical page plan reused on resume so the wiki structure stays stable across retries |
exploration_plan.failed_pages[] |
console.wiki_generations |
One object per exhausted page: key, title, error, and attempts for targeted follow-up retries |
status = complete_with_errors |
Wiki generation status row and status API response | Terminal state for partial success: usable pages were persisted, but at least one page still failed after retries |
No new resume endpoint was added for this feature. The existing full-generation trigger remains the user-facing entry point, and the status API surfaces complete_with_errors as a normal terminal value.
Known Trade-offs and Debt¶
-
Indexing runs inline on the gateway in direct mode. In
PRISM_QUEUE_MODE=direct(the default), indexing jobs run as asyncio tasks inside the gateway process. This is adequate for development but risks OOM on large repos in production. Cloud Run Jobs mode (PRISM_QUEUE_MODE=tasks) offloads indexing to a separate container. See TDR-004. -
Rate limiting uses SQL COUNT queries, not Redis. Per-tenant rate limiting queries
prism.usage_logwith a date range filter. This is adequate at early scale (<1,000 tenants) but will become a bottleneck under high query volume. Redis is the planned migration path. -
Connection pool is shared across all tenants. A single asyncpg pool (default 10 connections) serves all tenant queries. A tenant issuing many slow queries will consume pool connections, increasing latency for others. Per-tenant connection limits are not implemented.
-
RepoMap recalculation runs only on push.
get_module_map()reads frommodule_summarieswhich is updated during Tier 3 indexing (push webhook). During active development between pushes, the module map reflects the last pushed state. -
No automatic failover for Vertex AI. If the Vertex AI embedding API is unavailable, ingestion fails and search quality degrades (only BM25 and exact legs work). A fallback embedding provider is not configured in production.