Prism¶
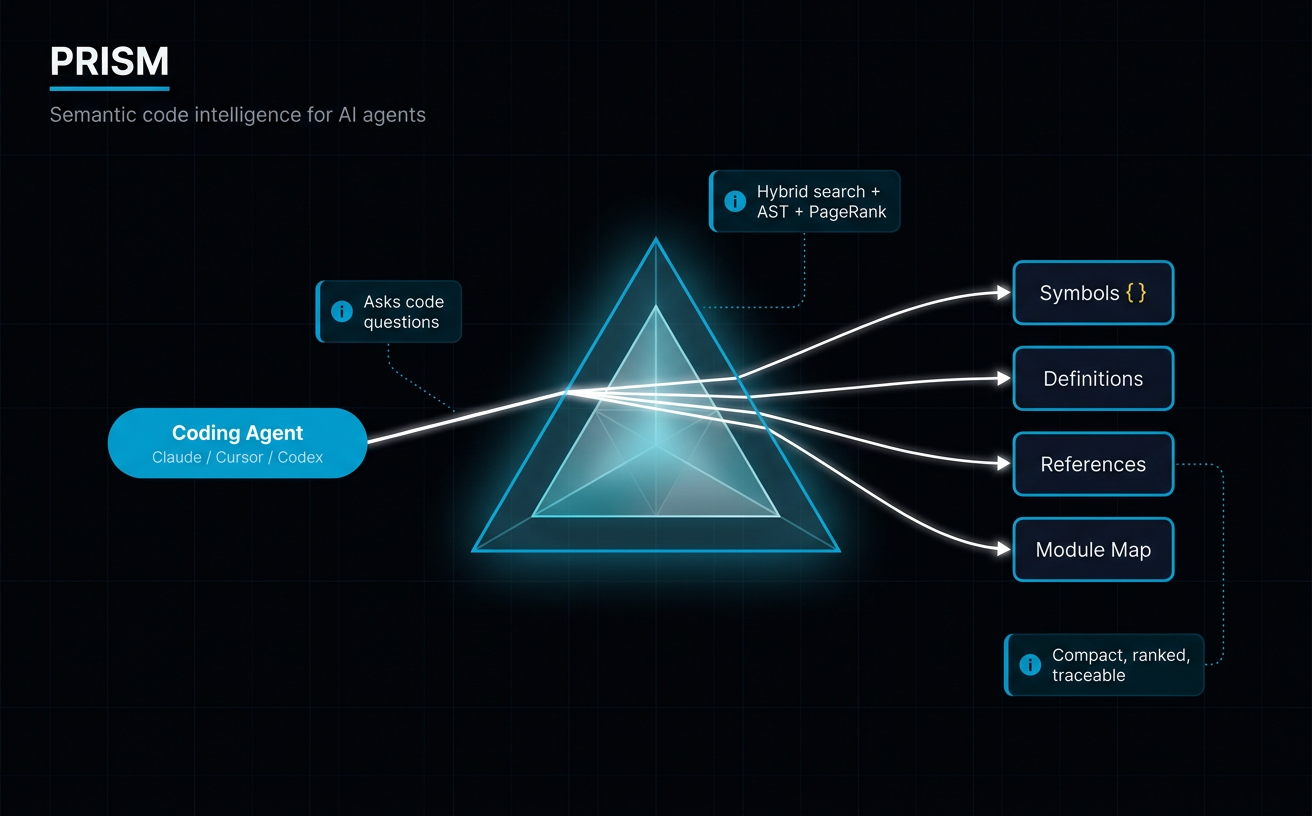
Prism refracts a codebase into precisely the right spectrum of context. The whole codebase is present, but only the relevant wavelengths are shown. No noise. No wasted tokens. Just the exact light needed to see clearly.
Code Intelligence for AI Agents and the Humans Working Alongside Them.
Turn a codebase into a queryable knowledge layer — a drop-in replacement for
grep and "read the whole file" that pays for its tokens many times over.
Instead of giving an AI assistant raw grep and a few thousand tokens of guesswork, Prism gives it a hosted index that understands the repo: its symbols, its imports, its architectural shape, and the natural-language meaning of every function in it.
Live gateway: https://prism-gateway-xvsemyikqq-oa.a.run.app
Two surfaces, one index¶
prismCLI — coding agents (Claude Code, Cursor, Continue) call it directly. Auto-overlay is on by default: dirty files are attached to every read so unpushed local edits are visible to search and refactor before they're committed.- Hosted MCP gateway — JWT-auth'd, per-tenant Postgres-schema-isolated, Streamable HTTP. Any non-editing agent can consume it: wiki agents, architect agents, Claude Desktop, ChatGPT, custom internal tooling.
Same gateway, same tokens, same index — two ergonomics for two audiences.
The indexing pipeline¶
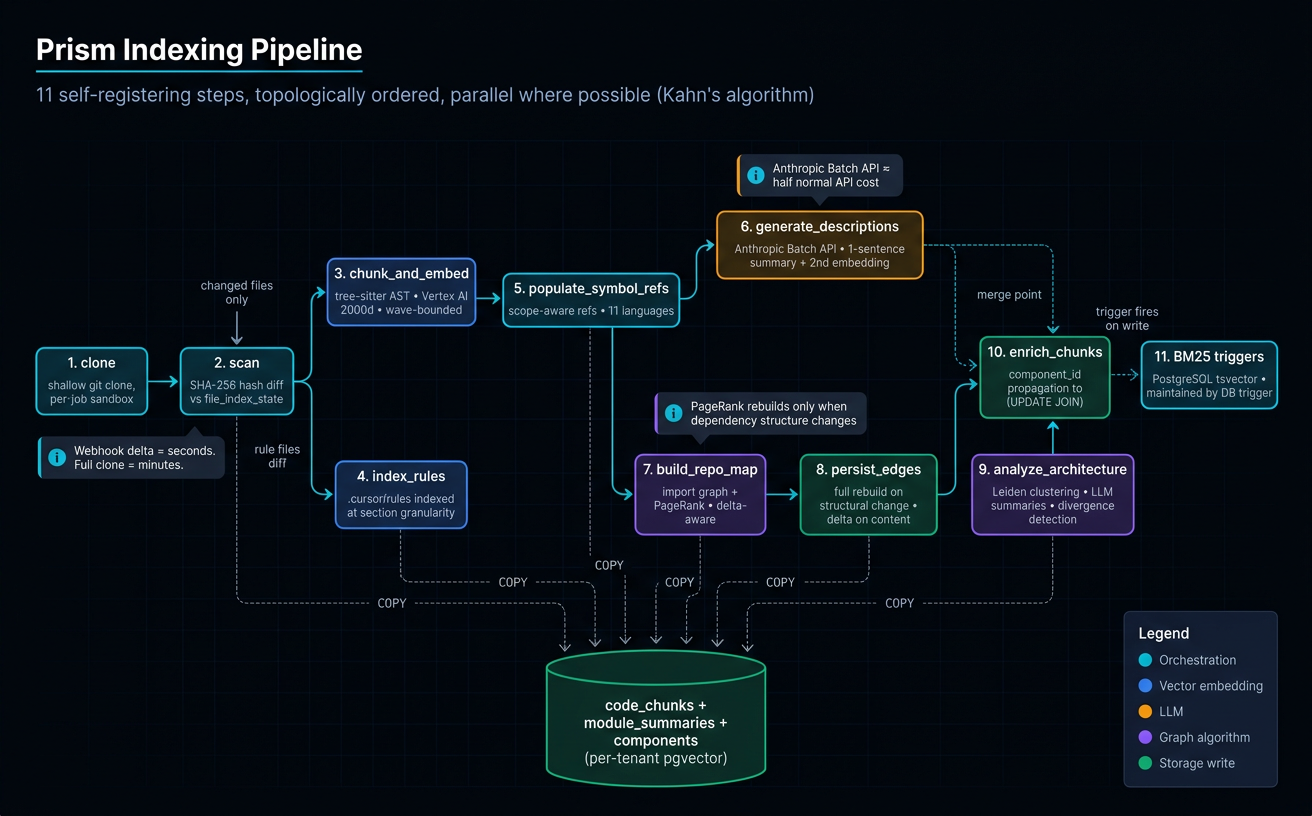
Prism's pipeline is a topologically-ordered DAG of self-registering steps (Kahn's algorithm). Each step is independently re-runnable; structural-change detection flips the pipeline between delta and full-rebuild modes per step.
| # | Step | What it gives you |
|---|---|---|
| 1 | clone | Shallow git clone into a per-job sandbox — safe parallel indexing across tenants |
| 2 | scan | SHA-256 file hash diff vs file_index_state — every later step processes only changed files |
| 3 | chunk_and_embed | Tree-sitter AST chunks at function/class boundaries + Vertex AI 2000-dim embeddings — function-level hits, not random text windows |
| 4 | index_rules | .cursor/rules/*.mdc indexed at section granularity — pull just "the factory-pattern rule," not 200 lines |
| 5 | populate_symbol_refs | Scope-aware refs across 11 languages — real callers, not noise from comments and imports |
| 6 | generate_descriptions | Anthropic Batch API → LLM summary → second embedding column — natural-language queries find code that doesn't contain those words |
| 7 | build_repo_map | Import graph + PageRank — files that everything depends on rise to the top |
| 8 | persist_edges | Two modes: full rebuild on structural change, delta for content edits — webhook indexing stays fast on monorepos |
| 9 | analyze_architecture | Leiden clustering + LLM summaries + divergence detection — real components an architect would recognize |
| 10 | enrich_chunks | Propagate component_id to every code chunk — search scoped to "the auth component" without folder knowledge |
| 11 | BM25 triggers | PostgreSQL tsvector maintained automatically — keyword leg always in sync, zero ops overhead |
Four-leg hybrid retrieval¶
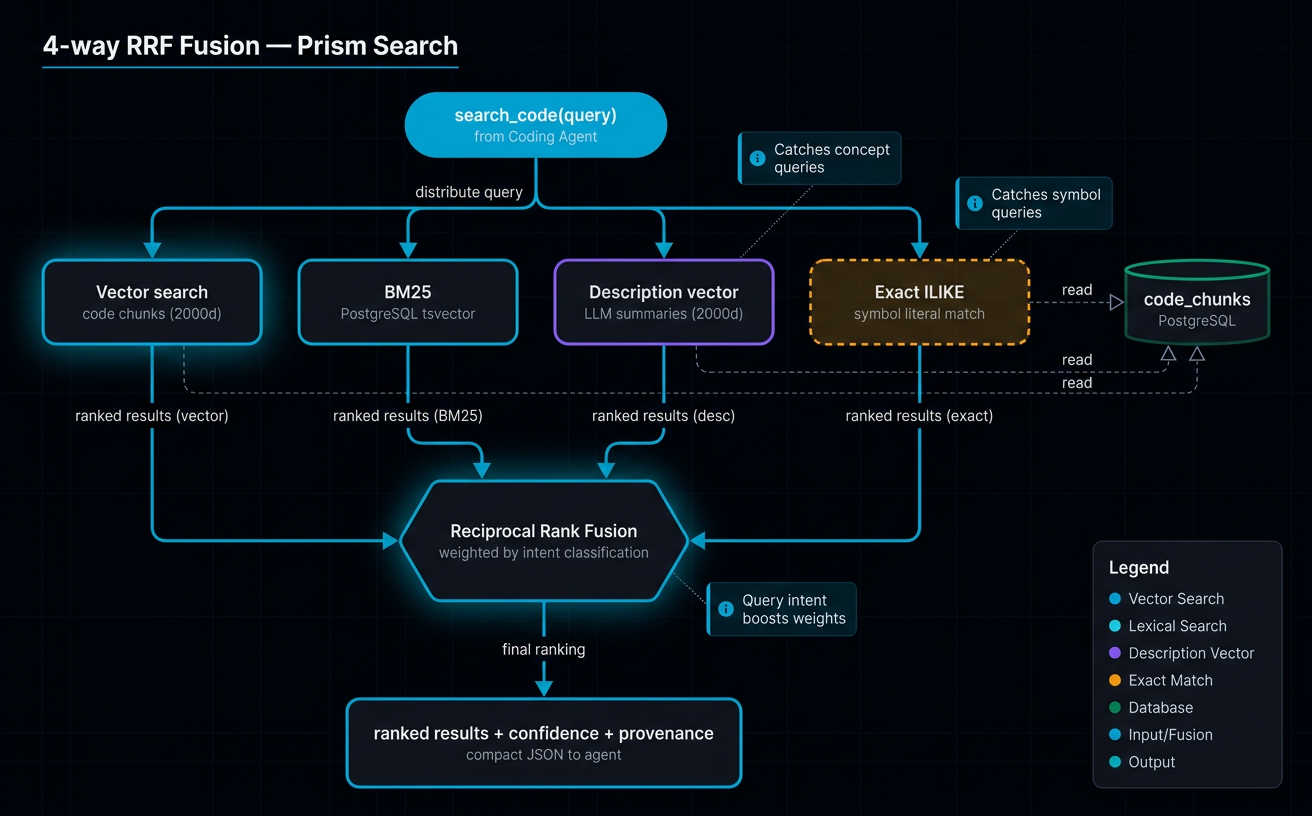
Most "hybrid" tools fuse vector + BM25. Prism fuses four legs via Reciprocal Rank Fusion (k=60, Cormack et al. 2009):
- Vector cosine over code embeddings
- BM25 over the
tsvectorfull-text index - Description vector — LLM summaries embedded as a second column, so natural-language queries match intent
- Exact ILIKE — grep superset; agents never need to fall back to text search
Every response carries confidence (high/medium/low), provenance (which legs
contributed), and next_actions.
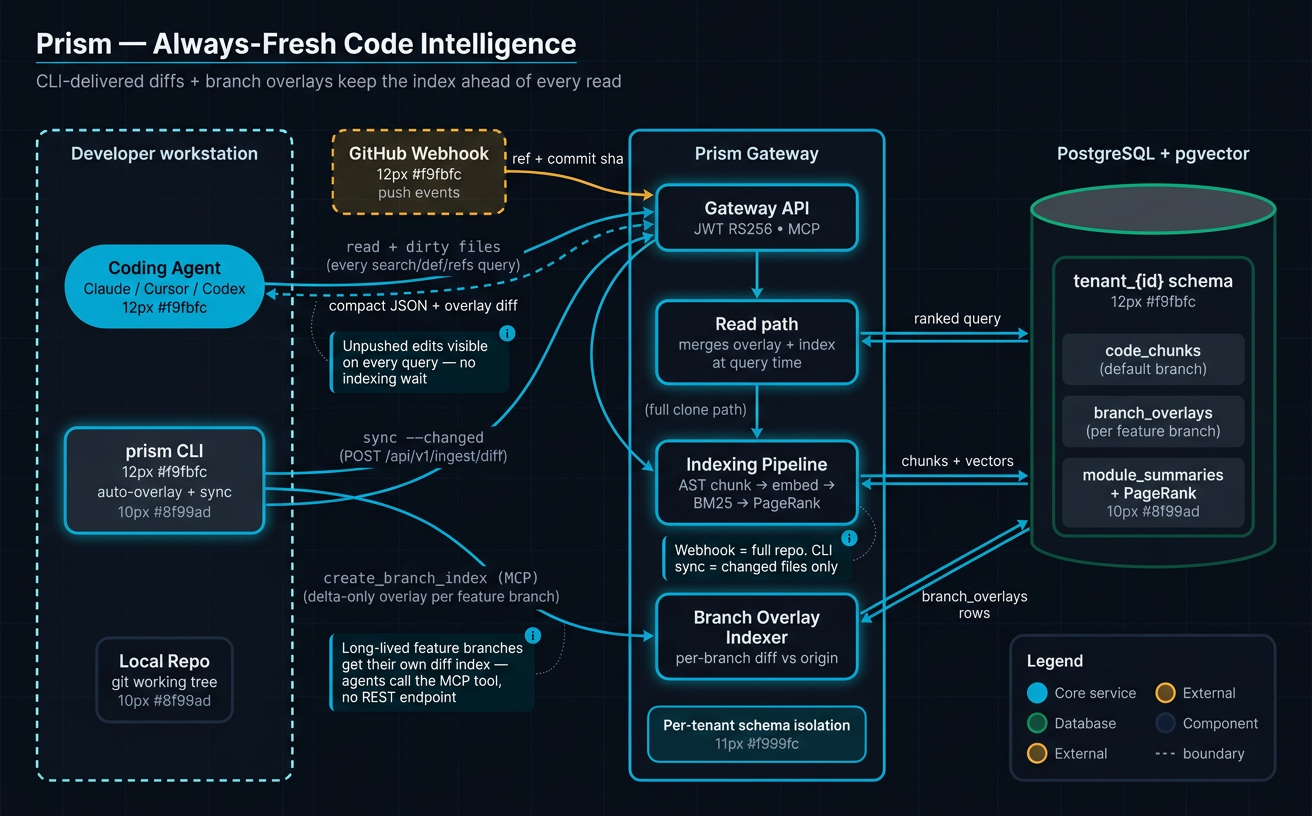
Always-fresh — incremental, branch overlays, webhooks¶
A code index that's a day stale is wrong. Prism is engineered so the index reflects the repo within seconds of a push.
- Incremental indexing. The scan step diffs file hashes; the rest of the pipeline re-processes only the delta. A 40k-chunk repo update from a typical PR completes in seconds, not minutes.
- CLI overlay (γ). Before answering, the CLI runs
git status, reads dirty files, and attaches them as an overlay payload. The gateway re-parses them in-memory. Local edits are visible to refactor analysis before they're committed. - Branch overlays. Long-lived feature branches get a delta-only overlay:
only files that differ from the default branch are stored, tagged with the
branch name. Agents create/delete via the
create_branch_index/delete_branch_indexMCP tools. Three-layer cleanup: GitHub delete webhook → PR-merge webhook → 14-day staleness reaper. - Webhook-triggered indexing. GitHub
pushhits Cloud Run; the pipeline runs scoped to changed files; PageRank rebuilds only on structural change.
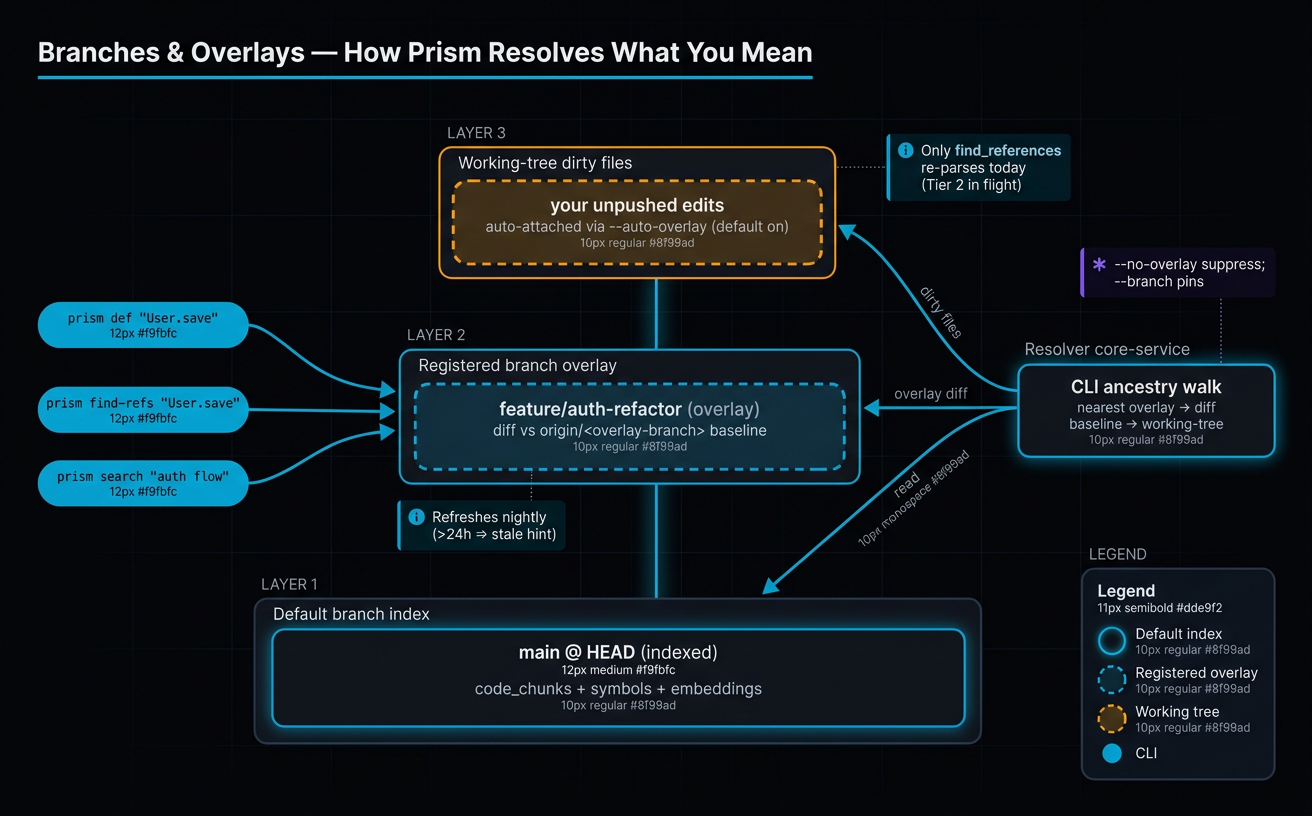
Every response carries indexed_at and index_age_seconds so agents can
trust-with-skepticism or trigger a reindex when the index is stale.
How agents use Prism¶
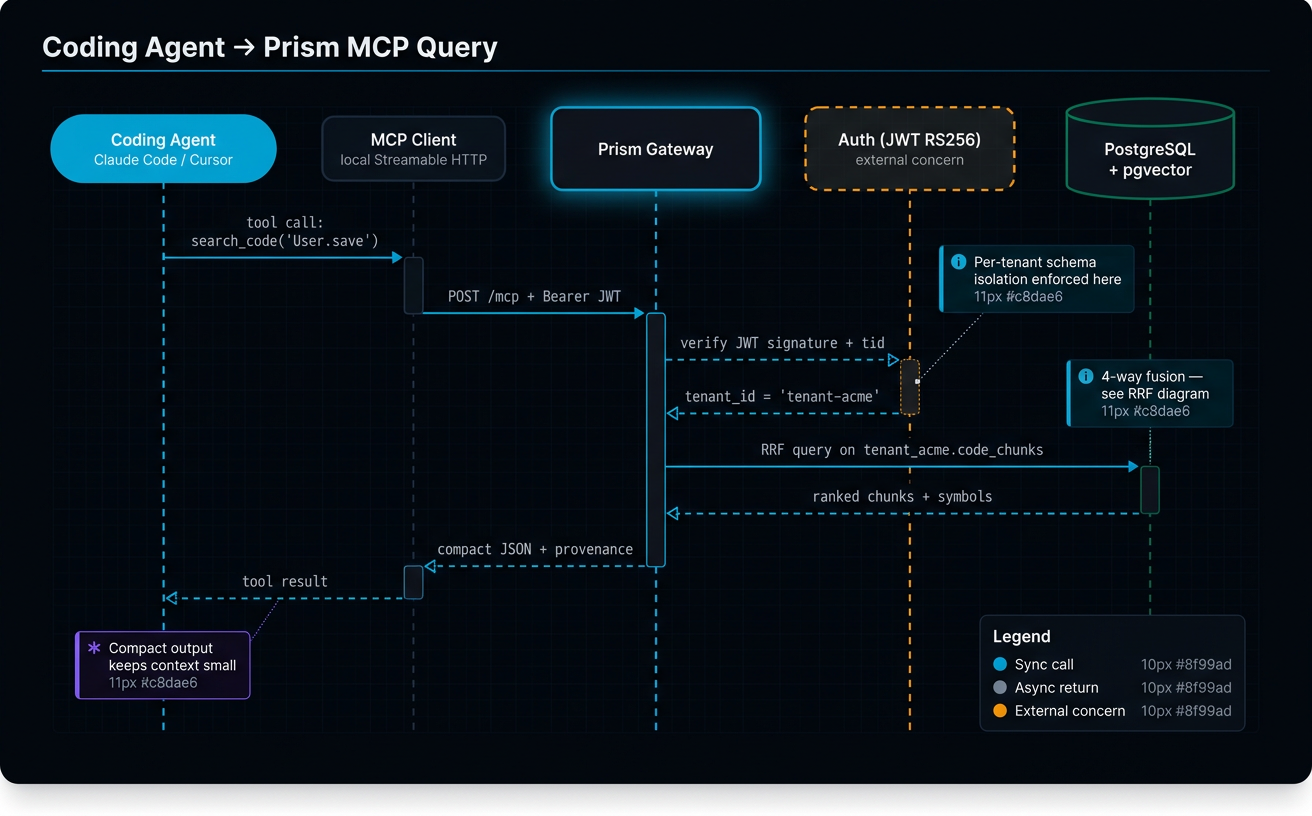
The CLI — prism (for coding agents)¶
| Command | What it does |
|---|---|
prism search "<query>" (alias grep) |
4-leg hybrid search with confidence + provenance |
prism find-refs "<symbol>" (alias refs) |
Scope-aware refs grouped by kind — --kind callers for refactoring |
prism def "<symbol>" |
Go-to-definition. ~200 tokens. Returns suggestions on miss |
prism body "<symbol>" |
Full source of one function/class/method |
prism outline <file> |
All symbols in a file, nested by class hierarchy. ~50 tokens |
prism module-map [path] [--query "<task>"] (alias map) |
PageRank architecture map; with --query re-ranks by relevance × PageRank |
prism deps <path> |
Module-level import graph (depends-on / depended-on-by) |
prism prepare-edit "<symbol>" |
Source + top 3 callers + test files + relevant rules + public-API warnings — replaces the 4–5-call pre-edit recipe |
prism check "<intent>" |
Reuse-first guard — up to 5 existing helpers ranked by description similarity |
prism find <pattern> |
Glob-style file finder |
prism ping / prism list-repos |
Health check and discovery |
Global flags: --repo Owner/Name, --branch <name>, --auto-overlay/--no-overlay, --pretty.
The MCP gateway — prism-hosted (for non-editing agents)¶
Same gateway, MCP-protocol surface. JWT RS256 auth. Streamable HTTP transport
(no SSE session state to lose). Per-tenant default repo via X-Prism-Repo header.
| Tool | Purpose | Cost |
|---|---|---|
search_code |
4-leg hybrid search. Filters: path_filter, source_only, include_file_context. Branch + overlay aware |
~200–1000 tok |
get_module_map |
PageRank-ranked file/directory hierarchy. Optional query re-ranks by task-relevance × PageRank. Tier classification |
~200–500 tok |
get_file_outline |
All symbols in a file, classes nested with their methods | ~300–1500 tok |
get_function_body |
Full source of a specific symbol | ~100–800 tok |
get_symbol_definition |
Go-to-definition. Batch up to 20 symbols. Fuzzy-match suggestions on miss | ~100–800 tok |
find_references |
Refs grouped by definitions / imports / callers / assignments. Batch up to 10. source_only strips test noise |
~200–500 tok |
get_dependencies |
Module-level import graph with configurable depth | ~20–400 tok |
get_architecture |
System overview (mode 1) or component drill-down (mode 2). LLM-summarized capabilities, divergence flags, top entry points | ~200–4000 tok |
get_repo_context |
Vision / architecture / readme / decisions docs. Filterable by section | ~80–800 tok |
get_codebase_conventions |
Inferred conventions (naming, layout, style) from the indexed code — also surfaces .cursor/rules sections |
~200–800 tok |
search_docs |
Search restricted to markdown / .mdc files only. Same shape as search_code |
~200–500 tok |
prepare_to_edit |
Pre-edit bundle: source + top callers + test files + relevant rules + warnings | ~500–2000 tok |
check_exists |
Intent-matched existing-helper finder | ~300–1000 tok |
create_branch_index / delete_branch_index |
Overlay lifecycle for long-lived feature branches | minimal |
list_repos / whoami / ping |
Discovery, identity, and health | ~20–500 tok |
Tool profiles (?profile=architect|devlead|developer|reviewer|wiki|full)
let agent frameworks scope which tools are advertised. The wiki profile, for
example, exposes only navigation/architecture/docs tools and hides the
editing-flow tools.
The moats¶
| Moat | What it means |
|---|---|
| 4-leg hybrid retrieval | Vector + BM25 + description vector + exact ILIKE fused via RRF. Description vector lets natural-language queries match LLM-summarized intent; exact ILIKE makes Prism a strict superset of grep |
| Architecture intelligence | PageRank + Leiden clustering — Prism knows which files matter and which files belong together. get_module_map ranks by structural centrality; get_architecture returns LLM-summarized components with their dependency graph |
| CLI overlay (γ) | git status → dirty-file payload → in-memory re-parse. Local edits visible to refactor analysis without forcing the agent to ship full-file payloads on every call |
| Adaptive response shaping | Compact ~200–400 tokens, ~500–3000 with snippets, automatically windowed when results are large. Confidence + provenance + token cost stamped on every response |
| Reuse-first discipline | check_exists surfaces existing helpers before duplicates get written; prepare_to_edit collapses the 4–5-call pre-edit recipe into one bundle |
| Per-tenant Postgres schema isolation | Physical schema separation (tenant_{id}) — not row-level filtering, not application-layer auth |
Beyond code: Wiki Agent + Architect Agent¶
Turn understanding a codebase from a months-long apprenticeship into a 10-minute conversation.
The Wiki Agent — "Give me a tour of this code"¶
Built on the wiki tool profile. A new engineer asks:
"What does this codebase do? How are the major components connected? Walk me through how a request flows from the API to the database."
The Wiki Agent calls get_architecture → get_module_map → get_dependencies
→ search_docs → get_function_body, and produces a guided tour with
citations — every claim links back to file and line.
Perfect for: onboarding · code-review prep · departing-engineer handover · executive questions like "how much of our codebase is auth-related?"
The Architect Agent — "Help me design the next thing"¶
Built on the architect tool profile. An architect asks:
"We're adding rate-limiting per tenant. What's the shape of the existing middleware layer? Are there patterns I should follow?"
The Architect Agent calls get_architecture → search_code("middleware") →
get_codebase_conventions(query="middleware") → get_dependencies →
get_repo_context(sections=["architecture","decisions"]), and outputs a
placement recommendation an Architecture Board would actually accept.
Perfect for: design reviews · refactor scoping · tech-debt triage · "can we reuse what we have or do we need a new component?"
Documentation¶
Guides¶
- Prism Setup Guide — Connect your IDE or chatbot to Prism (CLI for coding agents, MCP for chatbots)
- Indexing Pipeline — Step-by-step walk through the 11-step DAG
Decisions¶
- TDR-004: Indexing Queue Architecture — Move indexing to queue-based workers
Technology Stack¶
| Layer | Technologies |
|---|---|
| Runtime | Python 3.11+, Starlette ASGI, MCP SDK (Streamable HTTP) |
| Search | 4-leg hybrid (vector + BM25 + description vector + exact ILIKE), RRF fusion, Google Semantic Reranker |
| Embeddings | Vertex AI gemini-embedding-001 (2000-dimensional) |
| Descriptions | Anthropic Batch API (~half the cost of normal API calls) |
| Database | Cloud SQL PostgreSQL 16 + pgvector 0.8.1, per-tenant schemas |
| Parsing | Tree-sitter (48 languages), AST-based chunking; 11 languages for scope-aware symbol refs |
| Ranking | NetworkX PageRank for modules, Leiden clustering for components |
| Infrastructure | Google Cloud Run, Cloud SQL, Artifact Registry, Secret Manager |
| Auth | Developer tokens (permanent) + Firebase RS256 JWTs (1h expiry) |
The pitch in one sentence¶
Prism is the only code-intelligence platform that combines hybrid 4-leg semantic retrieval, PageRank-ranked architecture awareness, LLM-summarized chunk descriptions, scope-aware cross-language refs, branch overlays, and live git-overlay-via-CLI — served from a hosted multi-tenant gateway that scales from a single agent in your editor to a whole organization's AI workforce.